



Adapting LLMs for Specific Applications
To use an LLM for a company or a specific use case, it often needs additional information about the company, a specific domain, or the respective task. Depending on the context and use case, different methods or strategies come into question:
1. In-Context-Learning
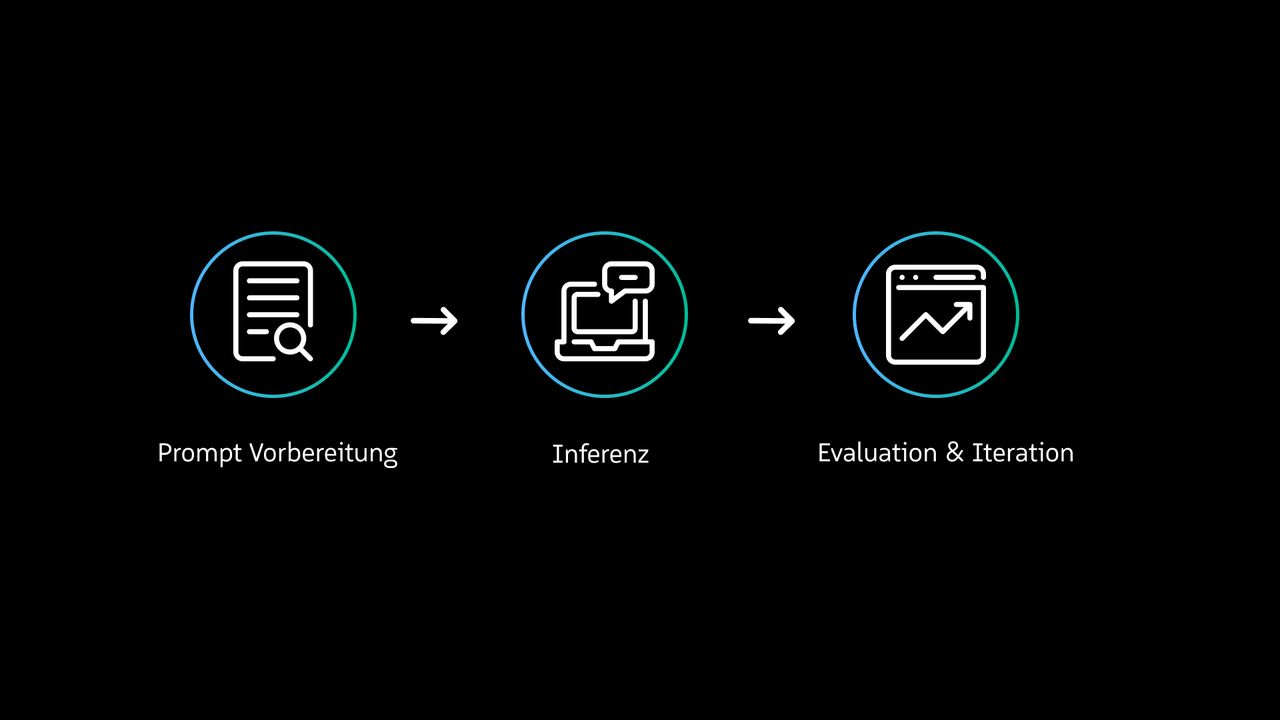
If only a small amount of information is needed, it can be given directly in the prompt during input. In so-called in-context learning, the model learns the task directly from the context. For example:“Read the following article and determine the appropriate newspaper section (e.g., politics, economy, panorama, sports, etc.):Berlin, March 2023 – In the middle of the Pacific, a freighter discovered a drifting wreck yesterday. Two survivors clung to the remains, seriously injured but alive. The cause of the accident remains unclear…”The model uses the provided input to recognize a pattern and make a new decision that it has not been trained on before. This method is suitable, for example, for text or style adaptations for personalized emails or product descriptions.
2. Fine-Tuning
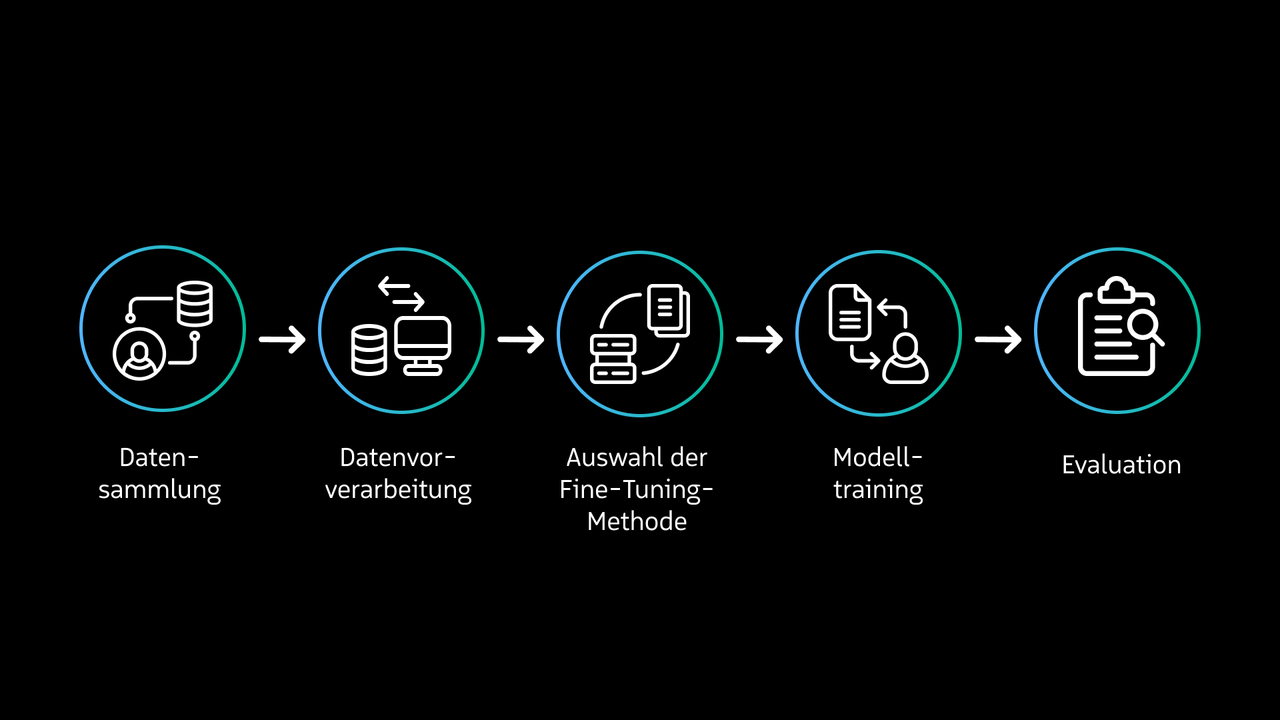
If a language model needs in-depth knowledge about a company, software, or a field of expertise, there is often not enough space for the required context in the input field. One solution is fine-tuning. Here, an already trained model is further trained with specific data. The language model already knows grammar and general language structures but is enriched with context-specific content. Although significantly less data is required for fine-tuning than for the original training, it still needs an appropriate amount of high-quality data in a standardized format. Incorrect information, poorly documented databases, or inferior image and table quality can negatively affect the model. A disadvantage of fine-tuning is that already integrated data can no longer be removed or easily updated. Fine-tuning is useful, for example, for brand-specific text creation: Companies train a model on their own marketing and communication guidelines to generate consistent content in the company's own style.
3. Retrieval Augmented Generation (RAG)
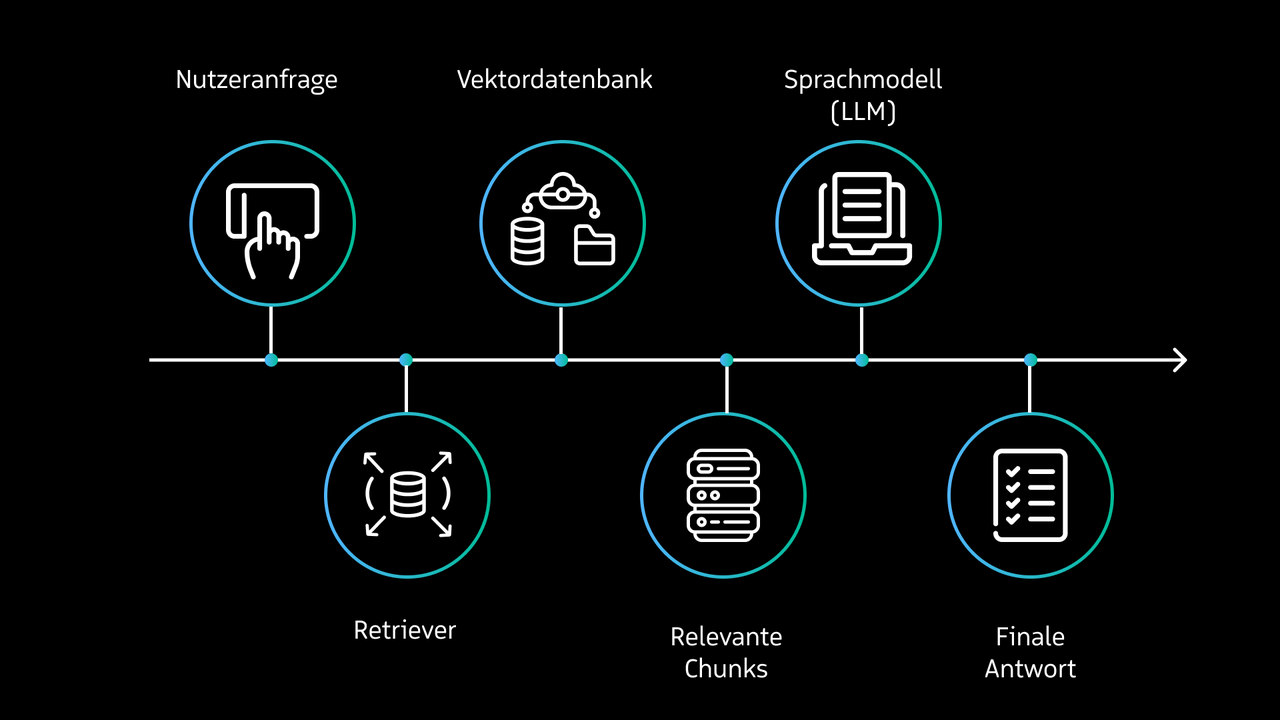
A particularly effective method for providing relevant and, above all, factually correct information is Retrieval Augmented Generation (RAG). Here, relevant data sources such as documentation, workshop recordings, explanatory videos, or instructions are stored in a vector database and divided into smaller sections (chunks). When a user makes a request, the system searches the database for the most suitable chunks. These are provided to the language model as context in the prompt to generate well-founded answers.
Advantages of RAG:
Flexibility: Databases can be expanded and updated as required
Precision: The answers are based on specific information
Efficiency: No complex fine-tuning of the model necessary
Challenges:
Extraction: Finding the right information chunks
Relevance: Selecting suitable documents for the request
Semantic Matching: Correctly capturing the contextual meaning
The RAG approach is advantageous in a variety of use cases, e.g., in dynamic knowledge databases for customer or IT support or personalized product recommendations based on real-time product data and user behavior.
In the AI Exploration Sprint, for example, we used the RAG method in our project with schrempp edv to develop a proof of concept for the integration of AI into the existing software.
)
)
)
)